Файл robots.txt необходим роботам поисковых систем, чтобы они могли понять, какие страницы и разделы сайта следует посещать и включать в индекс, а какие – не нужно. Запрещенные для посещения поисковыми ботами страницы не будут индексироваться и появляться в выдаче Яндекса, Google и прочих поисковиков.
Вот наглядный пример того, в чем разница между веб-ресурсом, у которого настроен файл robots, и сайтом без него:
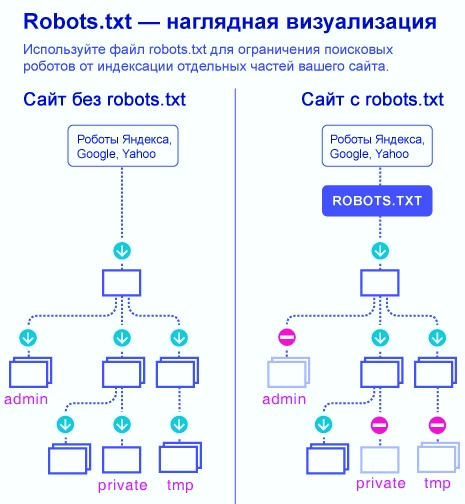
В данной статье я расскажу о нескольких способах правильной настройки robots.txt для популярного движка WordPress.
Оптимальный код файла для WordPress
User-agent: *
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /? # все параметры запроса с ?
Disallow: /*? # поиск
Disallow: /& # поиск
Disallow: /*& # поиск
Disallow: /author/ # архив автора
Disallow: /embed # все встраивания
Disallow: /page/ # все виды пагинации
Disallow: /trackback # уведомление о ссылках-трекбэках
Allow: /uploads # открываем uploads
Allow: /*.js # внутри /wp- (/*/ - для приоритета)
Allow: /*.css # внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php
Sitemap: https://domain.ru/sitemap.xml[sh_readmore link=»https://robotstxt.ru/files/wordpress-1/robots.txt.zip»]Скачать .zip[/sh_readmore]
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Теперь разберем, какие директивы в коде что означают:
1. Директива User-agent: * означает, что все правила, описанные ниже нее, касаются всех роботов поисковых систем. Если вы хотите прописать правила для одного определенного бота, вместо * нужно ввести его имя. Например:
- User-agent: Googlebot – для главного робота Гугла.
- User-agent: Yandex – для главного бота Яндекса.
Подробнее о директиве User-agent
2. Строка Allow: /uploads указывается, чтобы разрешить ботам вносить в индекс страницы, где присутствует /uploads. Нужно обязательно указать данное правило, потому что выше запрещены к индексированию страницы, которые начинаются с /wp-, а проблема в том, что /uploads присутствует в /wp-content/uploads.
Команда Allow: /uploads нужна для перебивания правила Disallow: /wp-, так как по ссылкам типа /wp-content/uploads/ могут располагаться изображения, важные для индексации. Помимо картинок есть вероятность присутствия прочих файлов, которые нет нужды запрещать включать в поиск. Строчку Allow допускается прописывать и до, и после Disallow.
3. Директивы Disallow: запрещают ботам переходить по ссылкам, начинающимся с:
- Disallow: /trackback — закрывает уведомления
- Disallow: /s или Disallow: /*? — закрывает страницы поиска
- Disallow: /page/ — закрывает все виды пагинации
Подробнее о директиве Dissalow
4. Строчка Sitemap: http://domain.ru/sitemap.xml сообщает поисковому боту о XML файле с картой сайта. Если на вашем ресурсе присутствует данный файл, укажите к нему полный путь. Если их несколько, нужно прописать путь отдельно к каждому из них.
Рекомендуется не закрывать от индексации фиды: Disallow: /feed.
Это связано с тем, что доступ к фидам нужен, к примеру, для подключения сайта к каналу Яндекс Дзен, Турбо страниц. Могут быть еще некоторые случаи, где нужны открытые фиды. Через feed передается контент в формате .rss. Если вы не знаете что это такое, то читайте более подробную статью — что такое RSS.
У фидов собственный формат в заголовках ответа, что позволяет поисковым системам понять, что это фид, а не HTML документ, и обрабатывать его по-другому.
А если вы не хотите передавать RSS, чтобы например у вас не воровали через него контент, то тогда надежнее отключить его с помощью специальных плагинов, например Disable Feeds.
Сортировка правил перед обработкой
Google и Яндекс обрабатывают правила Disallow и Allow без соблюдения порядка, в котором они прописаны в robots.txt. Поисковики сортируют директивы от коротких к длинным, после чего обрабатывают последнюю подходящую директиву.
Например, данная инструкция:
User-agent: *
Allow: /uploads
Disallow: /wp-Поисковые системы обработают следующим образом:
User-agent: *
Disallow: /wp-
Allow: /uploadsВ случае проверки ссылки типа /wp-content/uploads/file.jpg, директива Disallow сначала запретит ссылку с /wp-, а затем Allow разрешит ее индексировать, поэтому ссылка будет доступна для роботов.
На заметку. Запомните главное при сортировке правил: чем директива в файле robots.txt длиннее, тем
она приоритетнее. Когда директивы одинаковой длины, приоритетной становится Allow.
Стандартный файл robots для WordPress
Хотя первый метод является более современным и логичным, но я все же пользуюсь вторым файлом robots.txt. Потому что мне так спокойнее, что с помощью директивы Dissalow: /wp- я не запрещу что то нужное, поэтому я прописываю каждую папку отдельно.
Исходя из вышеперечисленных правок, у меня получается вот такой robots.txt:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /embed
Disallow: /trackback
Disallow: /page/
Disallow: /search
Disallow: /&
Disallow: /?
Disallow: /*?
Allow: /wp-admin/admin-ajax.php
Sitemap: http://domain.ru/sitemap.xml[sh_readmore link=»https://robotstxt.ru/files/wordpress-2/robots.txt.zip»]Скачать .zip[/sh_readmore]
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Доработка файла под свои цели
Если потребуется заблокировать еще какие-то страницы или разделы веб-ресурса, добавьте директиву Disallow. К примеру, желая скрыть от роботов все публикации в рубрике News, пропишите правило:
Disallow: /newsТак вы запретите ботам переходить по ссылкам типа http://domain.ru/news и закроете от индексации такие страницы:
- http://domain.ru/news;
- http://domain.ru/my/news/nazvanie/;
- http://domain.ru/category/newsletter-nazvanie.html.
Постоянно проверяйте, какие страницы проиндексированы поисковыми системами и находятся в выдаче. Сделать это можно с помощью оператора site:domain.ru.
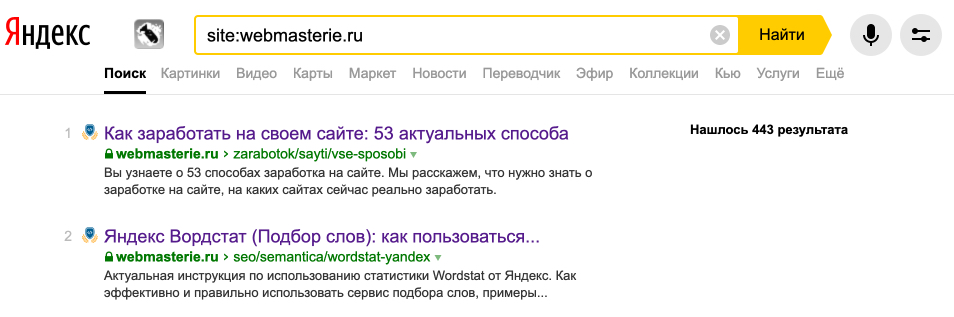
И если заметили мусорные, ненужные страницы, то блокируйте их в robots.txt.
Проверка файла и документация
Проверить корректность директив, прописанных в robots.txt, вы можете по ссылкам:
- Google Search Console https://www.google.com/webmasters/tools/dashboard?pli=1. Необходимо зарегистрировать сайт в панели вебмастера, если вы этого еще не сделали.
- Яндекс: http://webmaster.yandex.ru/robots.xml.
- Сервис для создания и проверки файла robots: https://seolib.ru/tools/generate/robots/.
- Сервис для создания robots.txt: http://pr-cy.ru/robots/.
- Документация Яндекса: https://yandex.ru/support/webmaster/controlling-robot/robots-txt.html.
- Документация Google: https://developers.google.com/search/reference/robots_txt.
Подробнее о проверке файла robots.txt
Динамический robots.txt
В CMS Вордпресс обработка запроса на файл robots производится отдельно. Вебмастеру нет нужды самостоятельно создавать в корневом каталоге сайта файл robots. Это не то что можно не делать, но и нужно, иначе плагины не смогут изменять созданный вебмастером файл, когда в этом появится необходимость.
Для изменения содержания динамического robots налету, через хук do_robotstxt, добавьте данный код в файл funtcions.php:
add_action( 'do_robotstxt', 'my_robotstxt' );
function my_robotstxt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "\r\n", $lines );
die; // обрываем работу PHP
}При переходе по ссылке http://example.com/robots.txt вы увидите следующий код:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/Заключение
Обязательно следите за актуальностью своего robots.txt. Проверяйте страницы на индексацию, чтобы там не было мусорных, не нужных страниц. Если такие заметили, то блокируйте их. При внесении изменений в файл robots.txt для уже рабочего веб-сайта результат будет видно не раньше, чем через 2-3 месяца.